Автор: д-р Игорь Юрисица
Научно-исследовательский институт Крембиля, Университетская сеть здравоохранения, Торонто
8 августа 2018 г.
Кратко
В этой развернутой новости команда Mapping Cancer Markers объясняет, как они определяют, какие гены и генные сигнатуры несут наибольшее обещание для диагностики рака легких. Они также вводят следующий тип рака - саркому - который будет добавлен в ближайшее время к проекту.
Проект Mapping Cancer Markers (MCM) продолжает обрабатывать рабочие единицы для набора данных о раке яичников. По мере накопления этих результатов мы продолжаем анализировать результаты MCM из набора данных о раке легкого. В этой новости мы обсудим предварительные выводы этого анализа. Кроме того, мы вводим набор данных саркомы, который будет нашим приоритетом на следующем этапе.
Паттерны биомаркеров семейства генов при раке легкого
В раке и биологии человека в целом несколько групп биомаркеров (гены, белки, микроРНК ит.д.) могут иметь сходные паттерны активности и, следовательно, клиническую полезность, помогая диагностировать, прогнозировать или предсказывать исход лечения. Для каждого подтипа рака можно было найти большое количество таких групп биомаркеров, каждый из которых обладал одинаковой прогностической способностью; однако современные статистические методы и методы на основе ИИ идентифицируют только один из данного набора данных.
У нас есть две основные цели в MCM: 1) найти хорошие группы биомаркеров для видов рака, которые мы изучаем, и 2) определить, как и почему эти биомаркеры образуют полезные группы так, что мы можем построить эвристический подход, который найдет такие группы для любых заболеваний без необходимости месячных вычислений на World Community Grid. Первая цель даст нам не только информацию, которая после валидации может быть полезна в клинической практике, но, что важно, она будет генерировать данные, которые мы будем использовать для подтверждения нашей эвристики.
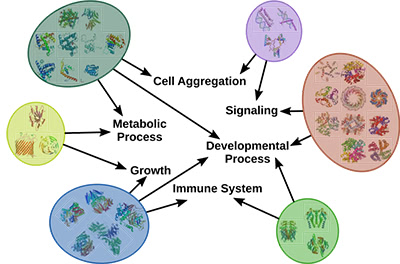
Иллюстрация 1: Белки группируются схожими взаимодействиями и аналогичными биологическими функциями.
Несколько групп биомаркеров существуют в основном из-за избыточности и сложной проводки биологической системы. Например, высоко взаимосвязанная сеть взаимодействия белка с белком человека позволяет нам видеть, как отдельные белки выполняют разнообразные молекулярные функции и вместе вносят вклад в конкретный биологический процесс, как показано выше на иллюстрации 1. Многие из этих взаимодействий изменяются между здоровыми и болезненными состояниями, что в свою очередь влияет на функции, которые переносят эти белки. Благодаря этим анализам мы стремимся создавать модели этих процессов, которые, в свою очередь, могут быть использованы для разработки новых терапевтических подходов.
Две специфические группы биомаркеров могут отличаться друг от друга, но выполняют эквивалентную роль, поскольку белки выполняют аналогичные молекулярные функции. Однако использование этих групп биомаркеров для стратификации пациентов может быть несэффективно. Группы биомаркеров часто не проверяются в новых когортах пациентов или при измерении с помощью различных биологических анализов, и есть тысячи возможных комбинаций для рассмотрения. Некоторые группы биомаркеров могут иметь все доступные реагенты, в то время как другие могут нуждаться в разработке (или быть более дорогими); они могут также иметь разную устойчивость, чувствительность и точность, влияя на их потенциал в качестве клинически полезных биомаркеров.
В настоящее время нет эффективного подхода к поиску всех хороших групп биомаркеров, необходимых для достижения определенной цели, таких как точное прогнозирование риска для пациента или ответа на лечение.
Первой целью проекта Mapping Cancer Markers является более глубокое понимание «правил» того, почему и как белки взаимодействют и могут быть объединены, чтобы сформировать группу биомаркеров, необходимую для понимания их роли и применимости. Поэтому мы используем уникальный вычислительный ресурс World Community Grid для систематического изучения ландшафта полезных групп биомаркеров для различных видов рака и целей (диагноз и прогноз). Таким образом, мы установили контрольный показатель для идентификации и проверки биомаркеров рака гена. Одновременно мы применяем неконтролируемые методы обучения, такие как иерархическая кластеризация к белкам, которые группируются по прогностической способности и биологической функции.
Комбинация этой кластеризации и паттернов World Community Grid позволяет нам идентифицировать обобщенные кластеры генов, которые обеспечивают более глубокое понимание молекулярного фона раковых заболеваний и дают более надежные группы биомаркеров генов для выявления и прогнозирования рака.
В настоящее время мы фокусируемся на результатах первой фазы из набора данных о раке легких, в котором основное внимание уделяется систематическому исследованию всего пространства потенциальных групп фиксированной длины биомаркеров.
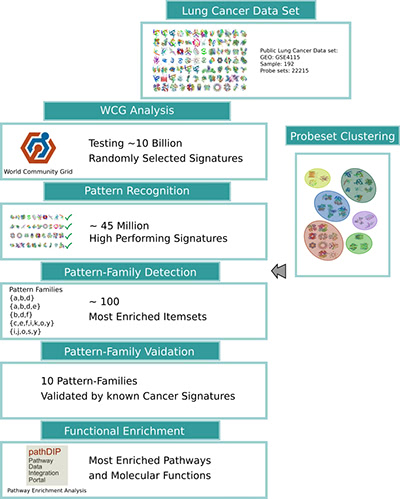
Иллюстрация 2: Рабочий процесс поиска семейства MCM-паттернов-генов. Результаты анализа World Community Grid в сочетании с неконтролируемой кластеризацией генов идентифицируют набор семейств генных образцов, обобщая группы биомаркеров. Наконец, результаты оцениваются с использованием известных биомаркеров рака и с использованием функциональных аннотаций, таких как сигнальные пути, функция и процессы онтологии генов.
Как показано выше на иллюстрации 2, World Community Grid рассчитала около 10 миллиардов случайно выбранных групп биомаркеров, чтобы помочь нам понять, какие распределения групп и комбинации биомаркеров выполняются хорошо, что в свою очередь мы будем использовать для проверки эвристических подходов. Анализ показал, что около 45 миллионов групп биомаркеров имели высокую прогностическую способность и прошли порог качества. Эта оценка дает нам подробную и систематическую картину того, какие гены и группы генов содержат самую ценную информацию для диагностики рака легких. Добавление сетевых данных и данных о взаимодействии с белками позволяет нам еще больше интерпретировать и понять, как и почему эти группы биомаркеров работают хорошо, и какие процессы и функции выполняют эти белки.
Одновременно мы использовали описанные данные о раке легкого для выявления групп подобных генов. Мы предполагаем, что эти гены или закодированные белки выполняют сходные биологические функции или участвуют в одних и тех же молекулярных процессах.
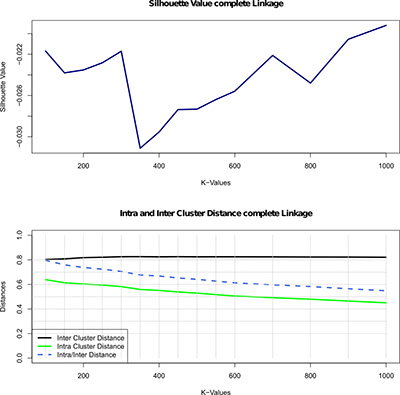
Иллюстрация 3: Оценка иерархической кластеризации данных о раке легкого с использованием полного параметра связи для различного количества групп, обозначенных значениями К (от 100 до 1000). На первом рисунке показано значение силуэта - метрика качества в этой кластеризации, т. е. показатель того, насколько хорошо каждый объект относится к его кластеру по сравнению с другими кластерами. Второй график отображает меж- и внутрикластерное расстояние и отношение расстояния внутри/между кластерами.
Чтобы найти соответствующие алгоритмы кластеризации и правильное количество групп генов (кластеров), мы используем различные меры для оценки качества каждой отдельной кластеризации. Например, в иллюстрации 3 (см. выше) показаны результаты оценки иерархической кластеризации для разных количеств кластеров. Чтобы оценить качество кластеризации, мы использовали значение силуэта (метод оценки согласованности в кластерах данных, т. е. показатель того, насколько хорошо каждый объект относится к его собственному кластеру по сравнению с другими кластерами). Высокое значение силуэта указывает на хорошую конфигурацию кластеризации, и на рисунке показано значительное увеличение значения силуэта в 700 группах генов. Поскольку это указывает на значительное повышение качества, мы впоследствии выбираем эту кластеризацию для дальнейшего анализа.
Не все комбинации биологических функций или их отсутствие приводят к развитию рака и будут иметь биологическое значение. На следующем этапе мы применяем статистический поиск для исследования того, какие комбинации кластеров наиболее распространены среди хорошо продуманных биомаркеров и, следовательно, приводят к генным группам или семействам шаблонов. Так как некоторые семейства генных образцов, вероятно, происходят даже случайным образом, мы используем анализ обогащения, чтобы гарантировать, что выбор содержит только семьи, которые встречаются значительно чаще, чем случайные.
На следующем этапе мы проверили выбранные обобщенные семейства генных образцов с использованием независимого набора из 28 наборов данных о раке легкого. В каждом из этих исследований сообщается о одной или нескольких группах биомаркеров генов, подверженных повышенному или низкому уровню, которые являются показателями рака легких.

Иллюстрация 4: Показаны выбор высокопроизводительных семейств паттернов и их поддержка 28-ю ранее опубликованными сигнатурами генов. Каждый круг на рисунке указывает силу поддержки: размер круга представляет количество кластеров в семье, где встречались значительно чаще в сигнатуре этого исследования. Цвет круга указывает среднее значение, рассчитанное для всех кластеров в семействе паттернов.
На рисунке 4 представлен выбор наиболее распространенных семейств паттернов и исследования, которые их поддерживают. Каждый круг на рисунке указывает силу поддержки: размер круга представляет собой количество кластеров в семье, где значительно чаще встречаются биомаркеры этого исследования. Цвет круга указывает среднее значение, рассчитанное для всех кластеров в семействе паттернов.
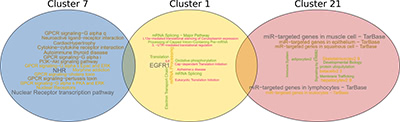
Иллюстрация 5: Одно из наиболее часто встречающихся семейств генных образцов - это комбинация кластеров 1, 7 и 21. Мы аннотировали каждый кластер с помощью путей используя pathDIP и визуализировали его с использованием текстовых облаков (чем больше слово/фраза, тем чаще такое случается).
Наконец, мы аннотировали наиболее эффективные семейства генных образцов и их кластеры генов с молекулярными функциями и путями, в которых участвуют гены или соответствующие белки. На иллюстрации 5 показан пример такого семейства генов-шаблонов, который содержит генные кластеры 7 , 1 и 21.
Облачная визуализация слов указывает, что кластер 7 участвует в путях, связанных с GPCR (рецептор, связанный с белками G) и NHR (рецепторы ядерных гормонов). Напротив, гены в кластере 1 сильно обогащены EGFR1 (рецептор эпидермального фактора роста), а также пути трансляционной регуляции. Показано, что мутации, влияющие на экспрессию EGFR1, трансмембранного белка, приводят к различным типам рака и, в частности, к раку легких (как мы показали ранее, например, (Petschigg et al., J Mol Biol 2017; Petschnigg et al. , Nat Methods 2014)). Аберрации увеличивают киназную активность EGFR1, приводя к гиперактивации путей передачи сигналов выживания в нисходящем направлении и последующего неконтролируемого деления клеток. Открытие EGFR1 положило начало разработке терапевтических подходов к различным типам рака, включая рак легких. Третья группа генов является общей целью микроРНК. Кластер 21 указывает на сильное участие в микроРНК, как мы и другие показали ранее (Tokar et al., Oncotarget 2018, Becker-Santos и др., J Pathology, 2016; Cinegaglia et al., Oncotarget 2016).
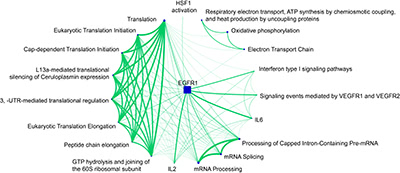
Иллюстрация 6: Оценка обогащенных путей для кластера 1. Здесь мы использовали наш общедоступный портал pathDIP для анализа обогащения путей (Rahmati et al., NAR 2017). Сеть была создана с помощью нашего инструмента визуализации и анализа сети NAViGaTOR 3 (http://ophid.utoronto.ca/navigator).
Заключительная иллюстрация оценивает 20 наиболее значительно обогащенных путей для кластера 1. Размер узлов пути соответствует количеству вовлеченных генов, а ширина ребер соответствует числу генов перекрытия между путями. Можно видеть, что все пути, связанные с переводом, сильно перекрываются. связанные с мРНК пути образуют еще один высокосвязный компонент на графике. Путь EGFR1 сильно перекрывается со многими другими путями, указывая на то, что гены, на которые влияют эти пути, вовлечены в аналогичный молекулярный механизм.
Саркома
После рака легких и яичников, мы сосредоточимся на саркоме. Саркомы представляют собой гетерогенную группу злокачественных опухолей, которые являются относительно редкими. Они обычно классифицируются в соответствии с морфологией и типом соединительных тканей, которые возникают у них, включая жир, мышцы, кровеносные сосуды, глубокие ткани кожи, нервы, кости и хрящ, которые составляют менее 10% всех злокачественных новообразований (Jain 2010). Саркомы могут возникать в любом месте человеческого тела, от головы до ног, могут развиваться у пациентов любого возраста, включая детей, и часто различаются по агрессивности, даже в пределах одного и того же субтипа органа или ткани (Honore 2015). Это говорит о том, что гистологическое описание типа органов и тканей не является достаточным для категоризации болезни и не помогает в выборе наиболее оптимального лечения.
Диагностика саркомы ставит особую дилемму не только из-за их редкости, но и из-за их многообразия, с более чем 70 гистологическими подтипами и нашего недостаточного понимания молекулярных характеристик этих подтипов (Jain 2010).
Поэтому в последних исследованиях основное внимание уделялось молекулярным классификациям саркомы на основе генетических изменений, таких как гены слияния или онкогенные мутации. В то время как исследования достигли значительных изменений в области местного контроля/восстановления конечностей, показатель выживаемости саркомы мягких тканей с высоким уровнем риска (STS) значительно не улучшился, особенно у пациентов с большой, глубокой, полноценной саркой (этап III) ( Кейн III 2018).
По этим причинам на следующем этапе анализа грид-сетей в мире мы сосредоточимся на оценке геномного фона саркомы. Мы будем использовать информацию и технологии секвенирования для получения более широкого знания между различными уровнями генетических аберраций и регулятивными последствиями. Мы предоставим более подробное описание данных и стимулов в следующей новости.
...
Другие новости
Мы добились крупного финансирование правительства Онтарио для наших исследований: Платформа биологии следующего поколения. Основной целью проекта является разработка новой интегрированной аналитической платформы и рабочего процесса для прецизионной медицины. Этот проект создаст доступный на международном уровне ресурс, который объединяет различные типы биологических данных, включая личную информацию о здоровье, раскрывая весь свой потенциал и делая ее более пригодной для исследований в рамках континуума здравоохранения: от генов и белков до путей, лекарств и людей.
Мы также опубликовали документы, описывающие несколько инструментов, порталов и приложений с нашими сотрудниками. Ниже мы перечисляем те, которые непосредственно или косвенно связаны с работой в World Community Grid:
...
Спасибо
Эта работа была бы невозможна без участия членов World Community Grid. Благодарим вас за щедрый вклад процессорных циклов и за ваш интерес к этому и другим проектам World Community Grid.
отсюда
Научно-исследовательский институт Крембиля, Университетская сеть здравоохранения, Торонто
8 августа 2018 г.
Кратко
В этой развернутой новости команда Mapping Cancer Markers объясняет, как они определяют, какие гены и генные сигнатуры несут наибольшее обещание для диагностики рака легких. Они также вводят следующий тип рака - саркому - который будет добавлен в ближайшее время к проекту.
Проект Mapping Cancer Markers (MCM) продолжает обрабатывать рабочие единицы для набора данных о раке яичников. По мере накопления этих результатов мы продолжаем анализировать результаты MCM из набора данных о раке легкого. В этой новости мы обсудим предварительные выводы этого анализа. Кроме того, мы вводим набор данных саркомы, который будет нашим приоритетом на следующем этапе.
Паттерны биомаркеров семейства генов при раке легкого
В раке и биологии человека в целом несколько групп биомаркеров (гены, белки, микроРНК ит.д.) могут иметь сходные паттерны активности и, следовательно, клиническую полезность, помогая диагностировать, прогнозировать или предсказывать исход лечения. Для каждого подтипа рака можно было найти большое количество таких групп биомаркеров, каждый из которых обладал одинаковой прогностической способностью; однако современные статистические методы и методы на основе ИИ идентифицируют только один из данного набора данных.
У нас есть две основные цели в MCM: 1) найти хорошие группы биомаркеров для видов рака, которые мы изучаем, и 2) определить, как и почему эти биомаркеры образуют полезные группы так, что мы можем построить эвристический подход, который найдет такие группы для любых заболеваний без необходимости месячных вычислений на World Community Grid. Первая цель даст нам не только информацию, которая после валидации может быть полезна в клинической практике, но, что важно, она будет генерировать данные, которые мы будем использовать для подтверждения нашей эвристики.
Иллюстрация 1: Белки группируются схожими взаимодействиями и аналогичными биологическими функциями.
Несколько групп биомаркеров существуют в основном из-за избыточности и сложной проводки биологической системы. Например, высоко взаимосвязанная сеть взаимодействия белка с белком человека позволяет нам видеть, как отдельные белки выполняют разнообразные молекулярные функции и вместе вносят вклад в конкретный биологический процесс, как показано выше на иллюстрации 1. Многие из этих взаимодействий изменяются между здоровыми и болезненными состояниями, что в свою очередь влияет на функции, которые переносят эти белки. Благодаря этим анализам мы стремимся создавать модели этих процессов, которые, в свою очередь, могут быть использованы для разработки новых терапевтических подходов.
Две специфические группы биомаркеров могут отличаться друг от друга, но выполняют эквивалентную роль, поскольку белки выполняют аналогичные молекулярные функции. Однако использование этих групп биомаркеров для стратификации пациентов может быть несэффективно. Группы биомаркеров часто не проверяются в новых когортах пациентов или при измерении с помощью различных биологических анализов, и есть тысячи возможных комбинаций для рассмотрения. Некоторые группы биомаркеров могут иметь все доступные реагенты, в то время как другие могут нуждаться в разработке (или быть более дорогими); они могут также иметь разную устойчивость, чувствительность и точность, влияя на их потенциал в качестве клинически полезных биомаркеров.
В настоящее время нет эффективного подхода к поиску всех хороших групп биомаркеров, необходимых для достижения определенной цели, таких как точное прогнозирование риска для пациента или ответа на лечение.
Первой целью проекта Mapping Cancer Markers является более глубокое понимание «правил» того, почему и как белки взаимодействют и могут быть объединены, чтобы сформировать группу биомаркеров, необходимую для понимания их роли и применимости. Поэтому мы используем уникальный вычислительный ресурс World Community Grid для систематического изучения ландшафта полезных групп биомаркеров для различных видов рака и целей (диагноз и прогноз). Таким образом, мы установили контрольный показатель для идентификации и проверки биомаркеров рака гена. Одновременно мы применяем неконтролируемые методы обучения, такие как иерархическая кластеризация к белкам, которые группируются по прогностической способности и биологической функции.
Комбинация этой кластеризации и паттернов World Community Grid позволяет нам идентифицировать обобщенные кластеры генов, которые обеспечивают более глубокое понимание молекулярного фона раковых заболеваний и дают более надежные группы биомаркеров генов для выявления и прогнозирования рака.
В настоящее время мы фокусируемся на результатах первой фазы из набора данных о раке легких, в котором основное внимание уделяется систематическому исследованию всего пространства потенциальных групп фиксированной длины биомаркеров.
Иллюстрация 2: Рабочий процесс поиска семейства MCM-паттернов-генов. Результаты анализа World Community Grid в сочетании с неконтролируемой кластеризацией генов идентифицируют набор семейств генных образцов, обобщая группы биомаркеров. Наконец, результаты оцениваются с использованием известных биомаркеров рака и с использованием функциональных аннотаций, таких как сигнальные пути, функция и процессы онтологии генов.
Как показано выше на иллюстрации 2, World Community Grid рассчитала около 10 миллиардов случайно выбранных групп биомаркеров, чтобы помочь нам понять, какие распределения групп и комбинации биомаркеров выполняются хорошо, что в свою очередь мы будем использовать для проверки эвристических подходов. Анализ показал, что около 45 миллионов групп биомаркеров имели высокую прогностическую способность и прошли порог качества. Эта оценка дает нам подробную и систематическую картину того, какие гены и группы генов содержат самую ценную информацию для диагностики рака легких. Добавление сетевых данных и данных о взаимодействии с белками позволяет нам еще больше интерпретировать и понять, как и почему эти группы биомаркеров работают хорошо, и какие процессы и функции выполняют эти белки.
Одновременно мы использовали описанные данные о раке легкого для выявления групп подобных генов. Мы предполагаем, что эти гены или закодированные белки выполняют сходные биологические функции или участвуют в одних и тех же молекулярных процессах.
Иллюстрация 3: Оценка иерархической кластеризации данных о раке легкого с использованием полного параметра связи для различного количества групп, обозначенных значениями К (от 100 до 1000). На первом рисунке показано значение силуэта - метрика качества в этой кластеризации, т. е. показатель того, насколько хорошо каждый объект относится к его кластеру по сравнению с другими кластерами. Второй график отображает меж- и внутрикластерное расстояние и отношение расстояния внутри/между кластерами.
Чтобы найти соответствующие алгоритмы кластеризации и правильное количество групп генов (кластеров), мы используем различные меры для оценки качества каждой отдельной кластеризации. Например, в иллюстрации 3 (см. выше) показаны результаты оценки иерархической кластеризации для разных количеств кластеров. Чтобы оценить качество кластеризации, мы использовали значение силуэта (метод оценки согласованности в кластерах данных, т. е. показатель того, насколько хорошо каждый объект относится к его собственному кластеру по сравнению с другими кластерами). Высокое значение силуэта указывает на хорошую конфигурацию кластеризации, и на рисунке показано значительное увеличение значения силуэта в 700 группах генов. Поскольку это указывает на значительное повышение качества, мы впоследствии выбираем эту кластеризацию для дальнейшего анализа.
Не все комбинации биологических функций или их отсутствие приводят к развитию рака и будут иметь биологическое значение. На следующем этапе мы применяем статистический поиск для исследования того, какие комбинации кластеров наиболее распространены среди хорошо продуманных биомаркеров и, следовательно, приводят к генным группам или семействам шаблонов. Так как некоторые семейства генных образцов, вероятно, происходят даже случайным образом, мы используем анализ обогащения, чтобы гарантировать, что выбор содержит только семьи, которые встречаются значительно чаще, чем случайные.
На следующем этапе мы проверили выбранные обобщенные семейства генных образцов с использованием независимого набора из 28 наборов данных о раке легкого. В каждом из этих исследований сообщается о одной или нескольких группах биомаркеров генов, подверженных повышенному или низкому уровню, которые являются показателями рака легких.
Иллюстрация 4: Показаны выбор высокопроизводительных семейств паттернов и их поддержка 28-ю ранее опубликованными сигнатурами генов. Каждый круг на рисунке указывает силу поддержки: размер круга представляет количество кластеров в семье, где встречались значительно чаще в сигнатуре этого исследования. Цвет круга указывает среднее значение, рассчитанное для всех кластеров в семействе паттернов.
На рисунке 4 представлен выбор наиболее распространенных семейств паттернов и исследования, которые их поддерживают. Каждый круг на рисунке указывает силу поддержки: размер круга представляет собой количество кластеров в семье, где значительно чаще встречаются биомаркеры этого исследования. Цвет круга указывает среднее значение, рассчитанное для всех кластеров в семействе паттернов.
Иллюстрация 5: Одно из наиболее часто встречающихся семейств генных образцов - это комбинация кластеров 1, 7 и 21. Мы аннотировали каждый кластер с помощью путей используя pathDIP и визуализировали его с использованием текстовых облаков (чем больше слово/фраза, тем чаще такое случается).
Наконец, мы аннотировали наиболее эффективные семейства генных образцов и их кластеры генов с молекулярными функциями и путями, в которых участвуют гены или соответствующие белки. На иллюстрации 5 показан пример такого семейства генов-шаблонов, который содержит генные кластеры 7 , 1 и 21.
Облачная визуализация слов указывает, что кластер 7 участвует в путях, связанных с GPCR (рецептор, связанный с белками G) и NHR (рецепторы ядерных гормонов). Напротив, гены в кластере 1 сильно обогащены EGFR1 (рецептор эпидермального фактора роста), а также пути трансляционной регуляции. Показано, что мутации, влияющие на экспрессию EGFR1, трансмембранного белка, приводят к различным типам рака и, в частности, к раку легких (как мы показали ранее, например, (Petschigg et al., J Mol Biol 2017; Petschnigg et al. , Nat Methods 2014)). Аберрации увеличивают киназную активность EGFR1, приводя к гиперактивации путей передачи сигналов выживания в нисходящем направлении и последующего неконтролируемого деления клеток. Открытие EGFR1 положило начало разработке терапевтических подходов к различным типам рака, включая рак легких. Третья группа генов является общей целью микроРНК. Кластер 21 указывает на сильное участие в микроРНК, как мы и другие показали ранее (Tokar et al., Oncotarget 2018, Becker-Santos и др., J Pathology, 2016; Cinegaglia et al., Oncotarget 2016).
Иллюстрация 6: Оценка обогащенных путей для кластера 1. Здесь мы использовали наш общедоступный портал pathDIP для анализа обогащения путей (Rahmati et al., NAR 2017). Сеть была создана с помощью нашего инструмента визуализации и анализа сети NAViGaTOR 3 (http://ophid.utoronto.ca/navigator).
Заключительная иллюстрация оценивает 20 наиболее значительно обогащенных путей для кластера 1. Размер узлов пути соответствует количеству вовлеченных генов, а ширина ребер соответствует числу генов перекрытия между путями. Можно видеть, что все пути, связанные с переводом, сильно перекрываются. связанные с мРНК пути образуют еще один высокосвязный компонент на графике. Путь EGFR1 сильно перекрывается со многими другими путями, указывая на то, что гены, на которые влияют эти пути, вовлечены в аналогичный молекулярный механизм.
Саркома
После рака легких и яичников, мы сосредоточимся на саркоме. Саркомы представляют собой гетерогенную группу злокачественных опухолей, которые являются относительно редкими. Они обычно классифицируются в соответствии с морфологией и типом соединительных тканей, которые возникают у них, включая жир, мышцы, кровеносные сосуды, глубокие ткани кожи, нервы, кости и хрящ, которые составляют менее 10% всех злокачественных новообразований (Jain 2010). Саркомы могут возникать в любом месте человеческого тела, от головы до ног, могут развиваться у пациентов любого возраста, включая детей, и часто различаются по агрессивности, даже в пределах одного и того же субтипа органа или ткани (Honore 2015). Это говорит о том, что гистологическое описание типа органов и тканей не является достаточным для категоризации болезни и не помогает в выборе наиболее оптимального лечения.
Диагностика саркомы ставит особую дилемму не только из-за их редкости, но и из-за их многообразия, с более чем 70 гистологическими подтипами и нашего недостаточного понимания молекулярных характеристик этих подтипов (Jain 2010).
Поэтому в последних исследованиях основное внимание уделялось молекулярным классификациям саркомы на основе генетических изменений, таких как гены слияния или онкогенные мутации. В то время как исследования достигли значительных изменений в области местного контроля/восстановления конечностей, показатель выживаемости саркомы мягких тканей с высоким уровнем риска (STS) значительно не улучшился, особенно у пациентов с большой, глубокой, полноценной саркой (этап III) ( Кейн III 2018).
По этим причинам на следующем этапе анализа грид-сетей в мире мы сосредоточимся на оценке геномного фона саркомы. Мы будем использовать информацию и технологии секвенирования для получения более широкого знания между различными уровнями генетических аберраций и регулятивными последствиями. Мы предоставим более подробное описание данных и стимулов в следующей новости.
...
Другие новости
Мы добились крупного финансирование правительства Онтарио для наших исследований: Платформа биологии следующего поколения. Основной целью проекта является разработка новой интегрированной аналитической платформы и рабочего процесса для прецизионной медицины. Этот проект создаст доступный на международном уровне ресурс, который объединяет различные типы биологических данных, включая личную информацию о здоровье, раскрывая весь свой потенциал и делая ее более пригодной для исследований в рамках континуума здравоохранения: от генов и белков до путей, лекарств и людей.
Мы также опубликовали документы, описывающие несколько инструментов, порталов и приложений с нашими сотрудниками. Ниже мы перечисляем те, которые непосредственно или косвенно связаны с работой в World Community Grid:
...
Спасибо
Эта работа была бы невозможна без участия членов World Community Grid. Благодарим вас за щедрый вклад процессорных циклов и за ваш интерес к этому и другим проектам World Community Grid.
отсюда