Исследовательская группа по картированию онкологических маркеров
31 января 2020 г.
Кратко
В этой общеобразовательной новости команда «Картирование маркеров рака» обсуждает прошлое (рак легких), настоящее (рак яичников) и будущее (саркома) проекта.
История вопроса
Проект «Картирование маркеров рака» (MCM) был разработан для выявления маркеров, ассоциирующихся с различными типами рака и путем уточнения процесса идентификации этих маркеров более эффективно идентифицировать подобные биомаркеры других заболеваний. Мы стремились проанализировать несколько наборов данных о раке, чтобы выявить потенциальные биомаркеры для этих раковых заболеваний, которые могли бы в конечном итоге помочь ученым и врачам раньше выявлять раковые заболевания и создавать персонализированные методы лечения. Первые три набора данных в плане MCM - это легкие, яичники и саркома, представляющие прошлое, настоящее и будущее MCM. Обработка легких завершена. Идет обработка маркера яичников, но он близок к завершению. Сейчас мы готовимся к переходу на саркому.
Обработка набора данных в World Community Grid за месяцы и годы приводит к огромному количеству данных, и эти данные не могут использоваться напрямую, но должны быть сопоставлены, отфильтрованы и проанализированы различными способами. Мы сосредоточились на этом шаге постобработки в нашей лаборатории.
В этой новости мы в основном обсудим некоторую работу, выполненную с обработанным набором данных легких, но сначала мы бросим быстрый взгляд на будущее.
Последние приготовления к саркоме
Предстоящий набор данных по саркоме будет самым сложным на сегодняшний день. Он содержит потенциальные биомаркеры, взятые из нескольких источников: измерения активности РНК, ДНК и белка, мутации и другие биологические методы.
С такой подробной информацией о каждом образце в наборе данных потребовалось некоторое усилие, чтобы уменьшить набор данных и размеры результатов до практических уровней. В настоящее время мы тестируем рабочие единицы нашего чернового набора данных и планируем работу.
В следующей новости будет объявлено о запуске новой фазы проекта MCM, сосредоточенной на саркоме, и будет предоставлено больше подробностей.
Результаты из набора данных легких
Биомаркеры в наборе данных легких МСМ измеряют активность тысяч генов. В совокупности эти биомаркеры охватывают большую часть человеческого генома. Большая часть работы с легкими MCM обрабатывается с помощью тщательного обзора сигнатур World Community Grid, случайным образом взятых из всего набора биомаркеров. Более короткая вторая фаза легких MCM получала сигнатуры от оптимизированных подмножеств этих биомаркеров.
Вклад вычислительных циклов в проект был экстраординарным. Члены World Community Grid обработали 4,5 триллиона кандидатов на рак легкого в основной фазе легкого MCM, 220 миллиардов в начальной экспериментальной фазе и 1,6 триллиона сигнатур в фазе оптимизации.
Мы обсудим некоторые выводы из основной фазы легких MCM в этой новости.
Вопрос о размере сигнатуры
MCM легких инспектировал сигнатуры нескольких размеров. Размеры варьировались от 5 биомаркеров до 100, при этом наибольшее внимание уделялось сигнатурам в диапазоне от 10 до 20 биомаркеров. Чтобы сигнатура рака успешно применялась в клинической практике, размер сигнатуры является компромиссом между диагностической силой, сложностью и стоимостью. Каждый биомаркер потенциально может добавлять диагностическую информацию к сигнатуре, повышая точность, но слишком большое количество биомаркеров также может добавлять шум и излишне увеличивать стоимость и сложность для практического использования в клинике.
На рисунке ниже показано влияние размера сигнатуры на пиковую точность. Почти для любого размера сигнатура, построенная из случайно выбранных биомаркеров, будет иметь низкую точность, но, протестировав достаточное количество таких сигнатур, а затем посмотрев на точность верхней фракции (скажем, верхней 0,01%), мы увидим эффект, производимый размером сигнатуры. Тщательно разработанные сигнатуры должны достигать той же точности, используя меньше биомаркеров.
Рисунок 1А
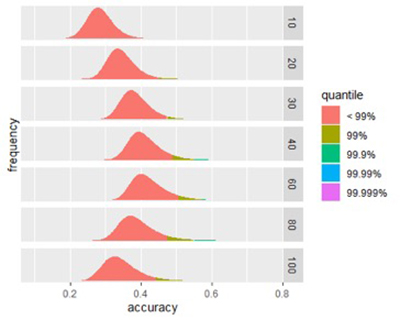
Рисунок 1Б
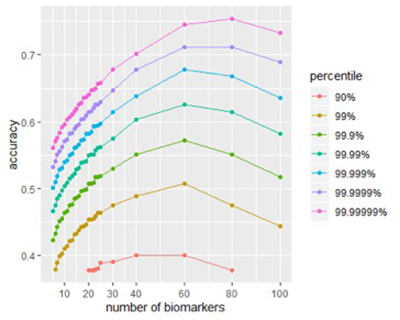
Рисунки 1A и 1Б: Размер влияет на потенциальную точность сигнатуры. (A) Распределение баллов по успешным сигнатурам разных размеров. (Б) Присмотритесь к влиянию размера точности оценки. Пиковая точность находится в сигнатурах между 40-80 биомаркерами.
Какие биомаркеры наиболее успешны?
В основной фазе легких MCM сигнатуры были построены из биомаркеров, выбранных случайным образом из набора данных. Таким образом, у каждого биомаркера была одинаковая вероятность появления в каждой новой сигнатуре. Это, однако, не означает, что все биомаркеры одинаково полезны - как мы уже говорили выше, случайная сигнатура, скорее всего, будет иметь низкую точность. Однако, если мы берем только самую точную часть сигнатур и видим, какие биомаркеры они содержат, мы видим, что несколько биомаркеров появляются часто, а остальные относительно редко. (Мы можем даже заметить закономерности в том, что определенные группы биомаркеров появляются вместе, как мы обсуждали в предыдущей новости.) Затем мы можем определить, насколько эффективен или полезен каждый биомаркер из того, как часто он появляется в этих главных сигнатурах.
Рисунок 2
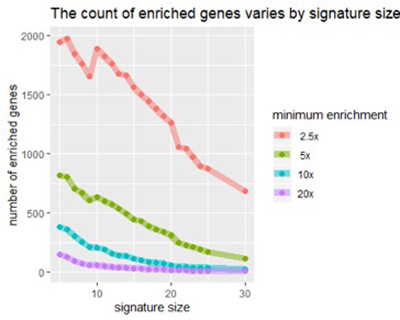
Рисунок 2: По мере увеличения размера сигнатуры мы видим уменьшение количества генов, обогащенных любым фактором (например, в 5 раз выше нормы)
Проанализировав полный набор результатов MCM в легких, мы можем подтвердить эффект, который мы заметили в предыдущих предварительных исследованиях: эффективность каждого биомаркера зависит от размера сигнатуры, по-разному влияя на каждый биомаркер. На рисунке ниже показан эффект для некоторых самых популярных биомаркеров.
Рисунок 3
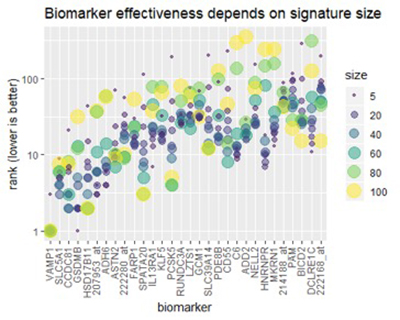
Рисунок 3: Размер сигнатуры рака легких определяет, насколько полезным может быть биомаркер. По мере роста размера подписи отдельные биомаркеры могут стать более или менее эффективными.
Насыщение пути среди лучших биомаркеров
Чтобы получить более высокое представление о биомаркерах, обнаруженных в наборе данных легких, мы исследовали их с точки зрения пути. Путь - это группа генов, которые взаимодействуют для выполнения одной и той же биологической функции. Мы поместили списки лучших биомаркеров в базу данных pathDIP нашей лаборатории [1], [2]. pathDIP представляет собой комплексную интегрированную базу данных известных путей (сигнальных каскадов), и, учитывая список генов, он найдет все пути, связанные с любым геном в списке. Наиболее полезно, он будет измерять обогащение каждого пути в вашем списке генов - степень, в которой путь имеет соединение выше среднего с вашим списком. Используя такой анализ, мы стремимся найти биологически значимую интерпретацию наших идентифицированных биомаркеров.
На рисунке ниже показаны результаты работы pathDIP.
Рисунок 4
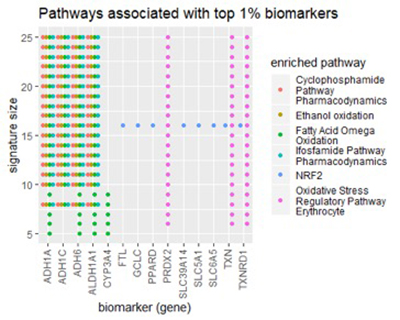
При большом количестве размеров подписи pathDIP постоянно находил пять путей, обогащенных в наших списках генов:
Все пять обогащенных путей связаны с обменом веществ, что означает распад химических веществ в организме. Любопытно, что первые два пути связаны конкретно с метаболизмом химиотерапевтических препаратов, циклофосфамида и ифосфамида. Последние три относятся либо к окислению, либо к предотвращению окислительного стресса (свободных радикалов) в эритроцитах.
Использование ресурса генной онтологии для описания лучших биомаркеров
Мы можем получить соответствующее представление из Ресурса генной онтологии (GO). GO классифицирует каждый ген с трех разных точек зрения: биологический процесс, молекулярная функция и клеточный компонент. На рисунках ниже показаны термины в категориях GO, которые часто встречаются в топ-1% биомаркеров.
Рисунок 5
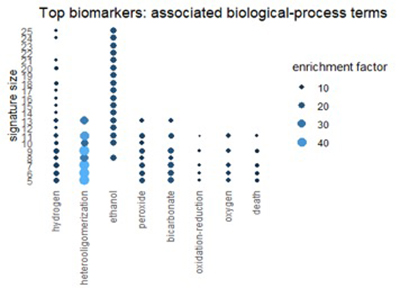
Рисунок 6
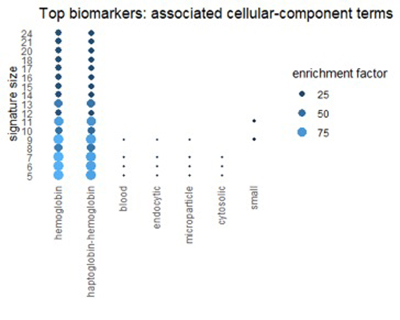
Рисунок 7
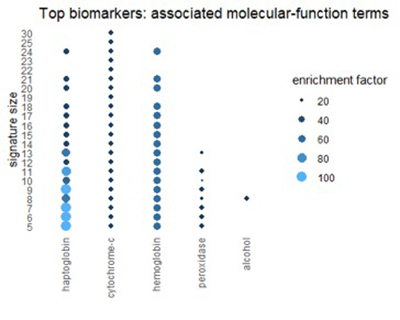
Многие термины отражают темы, обнаруженные в путях: окисление, алкоголь и химию эритроцитов.
Заглядывая вперед
Мы находимся в процессе расширения и объединения нескольких дополнительных анализов основной фазы данных легких и существенных анализов результатов легких второй фазы. После этого, в ожидании данные яичников. Для яичников, некоторые из тех же методов будут применяться, но некоторые должны быть адаптированы, а некоторые нам нужно будет разработать.
Короче говоря, проект MCM будет долгое время занимать нас. Тем временем, мы хотели бы поблагодарить вас за ваш интерес и за щедрое пожертвование вычислительной мощности в этот и другие проекты World Community Grid. Мы будем предоставлять новости чаще.
Дополнительные результаты
За последние два года мы опубликовали несколько оригинальных рукописей и несколько приложений с использованием наших инструментов и программ, многие из которых мы использовали для повышения ценности анализа MCM: ... на англ.
Другие новости
Из других новостей мы смогли получить несколько грантов для финансирования проекта, в том числе:
Важно отметить, что у нас также была возможность принять двух сторонников World Community Grid и MCM в нашем институте [3]. Дилан Буччи, ученик средней школы Sisler и учитель сети и кибербезопасности Роберт Эспозито, посетили наше исследовательское учреждение, чтобы встретиться с нами и нашими сотрудниками, учеными, которые используют результаты анализа. Нам было интересно узнать об их мотивации, а для них набраться опыта от прямых и косвенных связей с MCM.
Спасибо за всю предоставленную вычислительную мощность, которая делает возможным это исследование.
Команда MCM
на англ.
31 января 2020 г.
Кратко
В этой общеобразовательной новости команда «Картирование маркеров рака» обсуждает прошлое (рак легких), настоящее (рак яичников) и будущее (саркома) проекта.
История вопроса
Проект «Картирование маркеров рака» (MCM) был разработан для выявления маркеров, ассоциирующихся с различными типами рака и путем уточнения процесса идентификации этих маркеров более эффективно идентифицировать подобные биомаркеры других заболеваний. Мы стремились проанализировать несколько наборов данных о раке, чтобы выявить потенциальные биомаркеры для этих раковых заболеваний, которые могли бы в конечном итоге помочь ученым и врачам раньше выявлять раковые заболевания и создавать персонализированные методы лечения. Первые три набора данных в плане MCM - это легкие, яичники и саркома, представляющие прошлое, настоящее и будущее MCM. Обработка легких завершена. Идет обработка маркера яичников, но он близок к завершению. Сейчас мы готовимся к переходу на саркому.
Обработка набора данных в World Community Grid за месяцы и годы приводит к огромному количеству данных, и эти данные не могут использоваться напрямую, но должны быть сопоставлены, отфильтрованы и проанализированы различными способами. Мы сосредоточились на этом шаге постобработки в нашей лаборатории.
В этой новости мы в основном обсудим некоторую работу, выполненную с обработанным набором данных легких, но сначала мы бросим быстрый взгляд на будущее.
Последние приготовления к саркоме
Предстоящий набор данных по саркоме будет самым сложным на сегодняшний день. Он содержит потенциальные биомаркеры, взятые из нескольких источников: измерения активности РНК, ДНК и белка, мутации и другие биологические методы.
С такой подробной информацией о каждом образце в наборе данных потребовалось некоторое усилие, чтобы уменьшить набор данных и размеры результатов до практических уровней. В настоящее время мы тестируем рабочие единицы нашего чернового набора данных и планируем работу.
В следующей новости будет объявлено о запуске новой фазы проекта MCM, сосредоточенной на саркоме, и будет предоставлено больше подробностей.
Результаты из набора данных легких
Биомаркеры в наборе данных легких МСМ измеряют активность тысяч генов. В совокупности эти биомаркеры охватывают большую часть человеческого генома. Большая часть работы с легкими MCM обрабатывается с помощью тщательного обзора сигнатур World Community Grid, случайным образом взятых из всего набора биомаркеров. Более короткая вторая фаза легких MCM получала сигнатуры от оптимизированных подмножеств этих биомаркеров.
Вклад вычислительных циклов в проект был экстраординарным. Члены World Community Grid обработали 4,5 триллиона кандидатов на рак легкого в основной фазе легкого MCM, 220 миллиардов в начальной экспериментальной фазе и 1,6 триллиона сигнатур в фазе оптимизации.
Мы обсудим некоторые выводы из основной фазы легких MCM в этой новости.
Вопрос о размере сигнатуры
MCM легких инспектировал сигнатуры нескольких размеров. Размеры варьировались от 5 биомаркеров до 100, при этом наибольшее внимание уделялось сигнатурам в диапазоне от 10 до 20 биомаркеров. Чтобы сигнатура рака успешно применялась в клинической практике, размер сигнатуры является компромиссом между диагностической силой, сложностью и стоимостью. Каждый биомаркер потенциально может добавлять диагностическую информацию к сигнатуре, повышая точность, но слишком большое количество биомаркеров также может добавлять шум и излишне увеличивать стоимость и сложность для практического использования в клинике.
На рисунке ниже показано влияние размера сигнатуры на пиковую точность. Почти для любого размера сигнатура, построенная из случайно выбранных биомаркеров, будет иметь низкую точность, но, протестировав достаточное количество таких сигнатур, а затем посмотрев на точность верхней фракции (скажем, верхней 0,01%), мы увидим эффект, производимый размером сигнатуры. Тщательно разработанные сигнатуры должны достигать той же точности, используя меньше биомаркеров.
Рисунок 1А
Рисунок 1Б
Рисунки 1A и 1Б: Размер влияет на потенциальную точность сигнатуры. (A) Распределение баллов по успешным сигнатурам разных размеров. (Б) Присмотритесь к влиянию размера точности оценки. Пиковая точность находится в сигнатурах между 40-80 биомаркерами.
Какие биомаркеры наиболее успешны?
В основной фазе легких MCM сигнатуры были построены из биомаркеров, выбранных случайным образом из набора данных. Таким образом, у каждого биомаркера была одинаковая вероятность появления в каждой новой сигнатуре. Это, однако, не означает, что все биомаркеры одинаково полезны - как мы уже говорили выше, случайная сигнатура, скорее всего, будет иметь низкую точность. Однако, если мы берем только самую точную часть сигнатур и видим, какие биомаркеры они содержат, мы видим, что несколько биомаркеров появляются часто, а остальные относительно редко. (Мы можем даже заметить закономерности в том, что определенные группы биомаркеров появляются вместе, как мы обсуждали в предыдущей новости.) Затем мы можем определить, насколько эффективен или полезен каждый биомаркер из того, как часто он появляется в этих главных сигнатурах.
Рисунок 2
Рисунок 2: По мере увеличения размера сигнатуры мы видим уменьшение количества генов, обогащенных любым фактором (например, в 5 раз выше нормы)
Проанализировав полный набор результатов MCM в легких, мы можем подтвердить эффект, который мы заметили в предыдущих предварительных исследованиях: эффективность каждого биомаркера зависит от размера сигнатуры, по-разному влияя на каждый биомаркер. На рисунке ниже показан эффект для некоторых самых популярных биомаркеров.
Рисунок 3
Рисунок 3: Размер сигнатуры рака легких определяет, насколько полезным может быть биомаркер. По мере роста размера подписи отдельные биомаркеры могут стать более или менее эффективными.
Насыщение пути среди лучших биомаркеров
Чтобы получить более высокое представление о биомаркерах, обнаруженных в наборе данных легких, мы исследовали их с точки зрения пути. Путь - это группа генов, которые взаимодействуют для выполнения одной и той же биологической функции. Мы поместили списки лучших биомаркеров в базу данных pathDIP нашей лаборатории [1], [2]. pathDIP представляет собой комплексную интегрированную базу данных известных путей (сигнальных каскадов), и, учитывая список генов, он найдет все пути, связанные с любым геном в списке. Наиболее полезно, он будет измерять обогащение каждого пути в вашем списке генов - степень, в которой путь имеет соединение выше среднего с вашим списком. Используя такой анализ, мы стремимся найти биологически значимую интерпретацию наших идентифицированных биомаркеров.
На рисунке ниже показаны результаты работы pathDIP.
Рисунок 4
При большом количестве размеров подписи pathDIP постоянно находил пять путей, обогащенных в наших списках генов:
- Циклофосфамидный путь, фармакодинамика
- Путь ифосфамида, фармакодинамика
- Окисление этанола
- Омега окисление жирных кислот
- Регуляторный путь окислительного стресса (эритроцит)
Все пять обогащенных путей связаны с обменом веществ, что означает распад химических веществ в организме. Любопытно, что первые два пути связаны конкретно с метаболизмом химиотерапевтических препаратов, циклофосфамида и ифосфамида. Последние три относятся либо к окислению, либо к предотвращению окислительного стресса (свободных радикалов) в эритроцитах.
Использование ресурса генной онтологии для описания лучших биомаркеров
Мы можем получить соответствующее представление из Ресурса генной онтологии (GO). GO классифицирует каждый ген с трех разных точек зрения: биологический процесс, молекулярная функция и клеточный компонент. На рисунках ниже показаны термины в категориях GO, которые часто встречаются в топ-1% биомаркеров.
Рисунок 5
Рисунок 6
Рисунок 7
Многие термины отражают темы, обнаруженные в путях: окисление, алкоголь и химию эритроцитов.
Заглядывая вперед
Мы находимся в процессе расширения и объединения нескольких дополнительных анализов основной фазы данных легких и существенных анализов результатов легких второй фазы. После этого, в ожидании данные яичников. Для яичников, некоторые из тех же методов будут применяться, но некоторые должны быть адаптированы, а некоторые нам нужно будет разработать.
Короче говоря, проект MCM будет долгое время занимать нас. Тем временем, мы хотели бы поблагодарить вас за ваш интерес и за щедрое пожертвование вычислительной мощности в этот и другие проекты World Community Grid. Мы будем предоставлять новости чаще.
Дополнительные результаты
За последние два года мы опубликовали несколько оригинальных рукописей и несколько приложений с использованием наших инструментов и программ, многие из которых мы использовали для повышения ценности анализа MCM: ... на англ.
Другие новости
Из других новостей мы смогли получить несколько грантов для финансирования проекта, в том числе:
- Новые методы для интегративной вычислительной биологии от естественных наук и инженерного совета Канады,
- Интерактомное картирование связанных с болезнью белков с использованием расщепления интеин-опосредованного лигирования белков (SIMPL) из Genome Canada,
- Биологическая платформа следующего поколения от исследовательских фондов Онтарио
- Канадский институт здоровья в сотрудничестве с европейскими финансирующими агентствами
Важно отметить, что у нас также была возможность принять двух сторонников World Community Grid и MCM в нашем институте [3]. Дилан Буччи, ученик средней школы Sisler и учитель сети и кибербезопасности Роберт Эспозито, посетили наше исследовательское учреждение, чтобы встретиться с нами и нашими сотрудниками, учеными, которые используют результаты анализа. Нам было интересно узнать об их мотивации, а для них набраться опыта от прямых и косвенных связей с MCM.
Спасибо за всю предоставленную вычислительную мощность, которая делает возможным это исследование.
Команда MCM
на англ.